大模型参数是什么意思:7B、70B、5T 到底在说什么
刷科技新闻的时候经常看到这种说法:“这个模型有 70B 参数”,“训练用了 5T tokens”,“DeepSeek-V3 有 671B 参数”。
第一次看到这些数字,大部分人的反应是:这到底在说啥?
我用人话给你讲清楚。
什么是"参数"
先打个比方。
你学骑自行车的时候,大脑会不断调整一些"设置":身体往左偏多少度、手握把的力度、踩踏板的节奏。
这些"设置"就是你大脑里存储的经验值。
经过多次练习,这些值被调到刚好能让你保持平衡。
大模型的"参数"就是类似的东西。
每个参数是一个数字,代表模型内部某个连接的强度。
模型通过大量文本学习后,这些数字被调整到合适的值,使得模型能够理解和生成语言。
具体来说,参数主要存在于神经网络的权重矩阵中。
一个 7B 参数的模型,意味着它内部有 70 亿个这样的数字在协同工作。
B 和 T 是什么单位
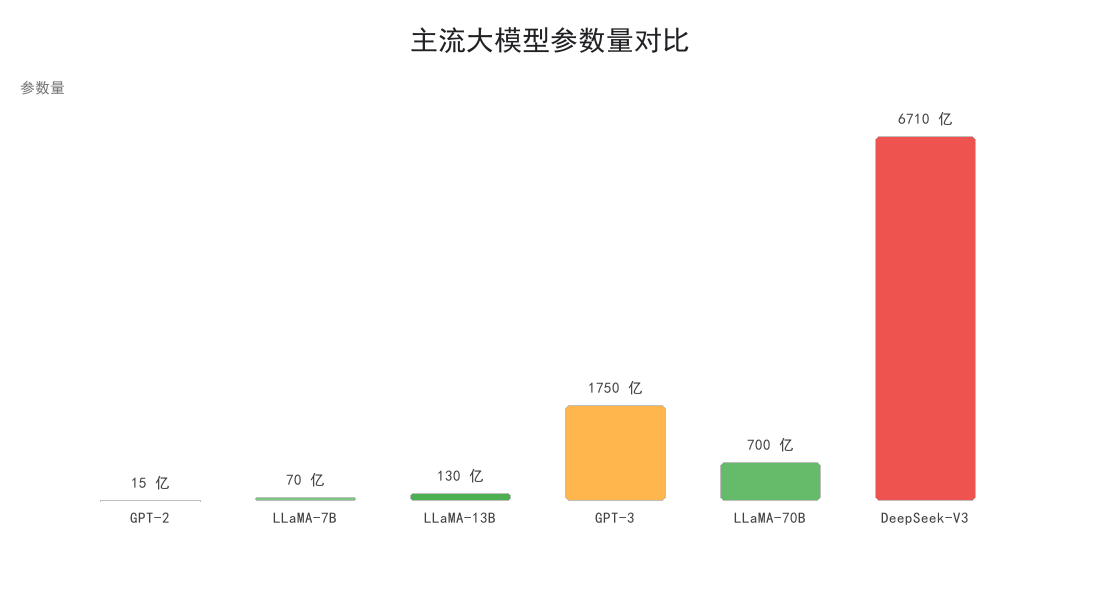
看到新闻里写 7B、70B、671B,这个 B 是 Billion(十亿)的缩写。
所以:
| 标记 | 含义 | 换算 |
|---|---|---|
| 1B | 10 亿 | 1,000,000,000 |
| 7B | 70 亿 | 7,000,000,000 |
| 13B | 130 亿 | 13,000,000,000 |
| 70B | 700 亿 | 70,000,000,000 |
| 175B | 1750 亿 | 175,000,000,000 |
| 671B | 6710 亿 | 671,000,000,000 |
而 T 是 Trillion(万亿)的缩写:
| 标记 | 含义 | 换算 |
|---|---|---|
| 1T | 1 万亿 | 1,000,000,000,000 |
| 1.8T | 1.8 万亿 | 1,800,000,000,000 |
| 5T | 5 万亿 | 5,000,000,000,000 |
| 15T | 15 万亿 | 15,000,000,000,000 |
所以当你看到"GPT-4 大约有 1.8T 参数",意思就是这个模型里有 1.8 万亿个可调节的数字。
“5T"是什么意思
这个要看上下文。5T 出现在两种场景中,含义完全不同:
场景一:5T 参数
如果说"这个模型有 5T 参数”,意味着模型有 5 万亿个参数。
目前(2026 年)公开发布的模型到这个量级,似乎只有 Claude Opus 模型
场景二:5T tokens 训练数据(更常见)
如果说"这个模型用了 5T tokens 训练",意味着模型在训练时看了 5 万亿个 token 的文本数据。
这是目前更常见的用法。
比如 LLaMA 3 用了大约 15T tokens 训练,DeepSeek-V3 用了约 14.8T tokens。这是什么概念呢?
- 一本 300 页的书大约有 10 万个 tokens
- 5T tokens 相当于 5000 万本书的文本量
- 整个英文维基百科大约 40 亿 tokens,5T tokens 相当于 1250 个维基百科
所以 5T tokens 训练数据意味着:这个模型"读过"的内容相当于 5000 万本书。

参数和训练数据是什么关系
一个容易混淆的点:参数量和训练数据量是两个独立的维度。
- 参数量(B/T):决定模型的"容量"有多大,能存储多少知识和模式
- 训练数据量(tokens):决定模型"见过"多少内容,学到了多少知识
打个比方:参数量像是一个人的大脑容量,训练数据量像是这个人读过多少书。
大脑容量大但没读过书,等于空有潜力;读了很多书但大脑容量小,记不住那么多内容。
两者需要匹配。
根据 2022 年 DeepMind 的 Chinchilla 论文,最优的训练策略是:训练 tokens 数量大约是参数量的 20 倍。也就是说,一个 7B 参数的模型,理想情况下应该用约 140B(1400 亿)tokens 来训练。
但后来的实践(比如 LLaMA 系列)发现,用更多数据训练小模型效果也很好。
LLaMA 7B 用了 1T tokens 训练(是 Chinchilla 建议的 7 倍),性能超过了用更少数据训练的更大模型。
参数越多就越好吗
不一定。参数量影响几个方面:
优势:
- 容量更大,能记住更多知识
- 涌现能力:某些能力只有参数量达到一定阈值才会出现
- 处理复杂任务的能力更强
代价:
- 推理(使用模型)时需要更多显存和算力
- 训练成本指数级增长
- 响应速度变慢
一个 7B 参数的模型大约需要 14GB 显存(FP16 精度),一张消费级显卡就能跑。
而 70B 参数的模型需要约 140GB 显存,至少要 2 张 A100 80GB 才能推理。
671B 参数的模型更是需要整个 GPU 集群。
这也是为什么业界越来越重视 MoE(混合专家模型)架构。
比如 DeepSeek-V3 虽然总参数有 671B,但每次推理只激活其中 37B 参数,大大降低了计算成本。
用 Go 估算模型显存占用
下面这段代码可以帮你快速估算一个模型需要多少显存:
package main
import "fmt"
func main() {
// 常见模型参数量(单位:十亿)
models := []struct {
Name string
Params float64 // 十亿
}{
{"LLaMA-7B", 7},
{"LLaMA-13B", 13},
{"LLaMA-70B", 70},
{"GPT-3", 175},
{"DeepSeek-V3 (全量)", 671},
{"DeepSeek-V3 (激活)", 37},
}
fmt.Println("模型显存估算(推理阶段)")
fmt.Println("================================")
for _, m := range models {
// FP16 精度:每个参数 2 字节
fp16GB := m.Params * 1e9 * 2 / (1024 * 1024 * 1024)
// INT8 量化:每个参数 1 字节
int8GB := m.Params * 1e9 * 1 / (1024 * 1024 * 1024)
// INT4 量化:每个参数 0.5 字节
int4GB := m.Params * 1e9 * 0.5 / (1024 * 1024 * 1024)
fmt.Printf("\n%s (%s 参数)\n", m.Name, formatParams(m.Params))
fmt.Printf(" FP16: %.1f GB\n", fp16GB)
fmt.Printf(" INT8: %.1f GB\n", int8GB)
fmt.Printf(" INT4: %.1f GB\n", int4GB)
}
}
func formatParams(billions float64) string {
if billions >= 1000 {
return fmt.Sprintf("%.1fT", billions/1000)
}
return fmt.Sprintf("%.0fB", billions)
}运行结果大概是这样的:
LLaMA-7B (7B 参数)
FP16: 13.0 GB
INT8: 6.5 GB
INT4: 3.3 GB
LLaMA-70B (70B 参数)
FP16: 130.4 GB
INT8: 65.2 GB
INT4: 32.6 GB这就是为什么量化技术这么重要——INT4 量化可以把 70B 模型压缩到单张 A100 40GB 能跑的程度。
常见问题
7B 和 7b 有区别吗?
没区别。7B 和 7b 都是 7 Billion(70 亿)的意思,只是大小写风格不同。
有些命名规范用大写 B(如 LLaMA-70B),有些用小写 b(如 qwen2-7b),含义完全相同。
“参数"和"权重"是一回事吗?
在日常讨论中基本等同。
严格来说,“权重"只是参数的一种(神经网络中连接的强度值),还有"偏置"也算参数。但偏置数量远少于权重,所以说"70B 参数"和"70B 权重"差别可以忽略。
为什么有些模型标注 MoE,参数量特别大?
MoE(Mixture of Experts,混合专家模型)把模型分成多个"专家"子网络,每次只激活一部分。DeepSeek-V3 总参数 671B,但每次推理只用 37B,所以实际推理成本跟 37B 模型差不多,但性能接近更大的密集模型。
训练一个 7B 模型要花多少钱?
粗略估算:训练 7B 模型用 1T tokens,大约需要 6000 GPU 小时(A100 80GB)。按云服务价格约 2 美元/GPU 小时计算,训练一次大约 1.2 万美元。70B 模型则需要约 100 万美元以上。
“5T tokens"的数据是从哪来的?
主要来源包括:网页抓取(Common Crawl)、书籍、论文、代码(GitHub)、维基百科、论坛帖子等。高质量的训练数据需要大量清洗和去重,原始数据可能是最终使用量的 10 倍以上。
总结
大模型的"参数"就是模型内部存储知识的数字——类似大脑突触的连接强度。参数越多,模型容量越大,能力越强,但成本也越高。
看到数字后面的字母就知道意思了:
- B = Billion = 10 亿:7B 就是 70 亿参数
- T = Trillion = 1 万亿:1.8T 就是 1.8 万亿参数
而"5T tokens"通常指训练数据量——模型学习了 5 万亿个文本片段,相当于读了 5000 万本书。
参数量决定模型的上限,训练数据决定模型能达到上限的多少。两者配合,才能训练出一个好模型。
如果你对大模型的其他概念有疑问(比如什么是 token、什么是 transformer、什么是 attention),欢迎评论区留言。
版权声明
未经授权,禁止转载本文章。
如需转载请保留原文链接并注明出处。即视为默认获得授权。
未保留原文链接未注明出处或删除链接将视为侵权,必追究法律责任!
本文原文链接: https://fiveyoboy.com/articles/llm-parameters-explained/
备用原文链接: https://blog.fiveyoboy.com/articles/llm-parameters-explained/