企业大模型治理,到底该怎么做才不出事?
去年到今年,几乎所有中大型公司都在干一件事:把大模型塞进业务里。
客服、代码、营销、合同审核,能接的都接了。
但塞进去之后呢?很多团队发现,效率是上来了,麻烦也跟着来了——客户隐私被模型吐出去、生成的方案瞎编数据、有人用提示词把内部系统骗得团团转。
这就是为什么「企业大模型治理」突然变成了一个绕不开的话题。
它不是一句口号,而是一整套你必须落地的机制。
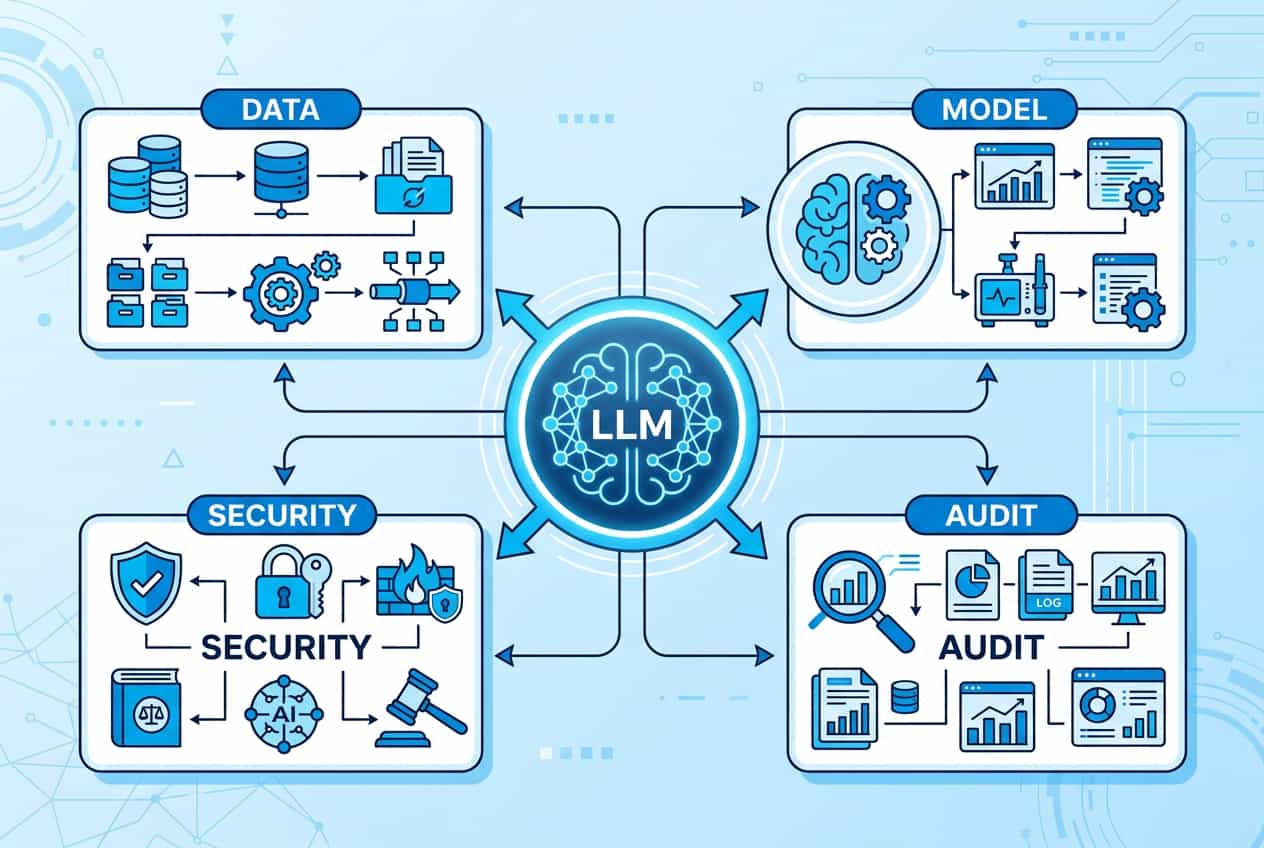
大模型治理到底是什么?
企业大模型治理是一套围绕 LLM 全生命周期的管理机制,目标是让模型在带来生产力的同时,风险、合规和成本都处于可控范围。
它覆盖四件事:数据怎么进、模型怎么管、安全怎么守、运行怎么审。
说白了,传统的数据治理管的是表和字段,大模型治理还得多管两件事:一个是「不可解释的输出」,一个是「不断变化的攻击面」。
这两点,是过去 IT 治理体系里没有的。
根据 Gartner 2025 年的一份调研,预计到 2026 年底,将超过 60% 的企业 AI 项目会因为治理缺失而被推迟或下线。
这个数字挺扎心的,但和先生情况差不多,很多项目在 POC 阶段跑得飞快,一到上线就卡在合规和安全评审。
为什么企业必须重视它?
我个人的感受是,大模型这东西和过去的 SaaS 工具不一样。
SaaS 是确定性的,输入 A 出 B;大模型是概率性的,输入 A 可能出 B,也可能出一段你完全没预料到的 C。
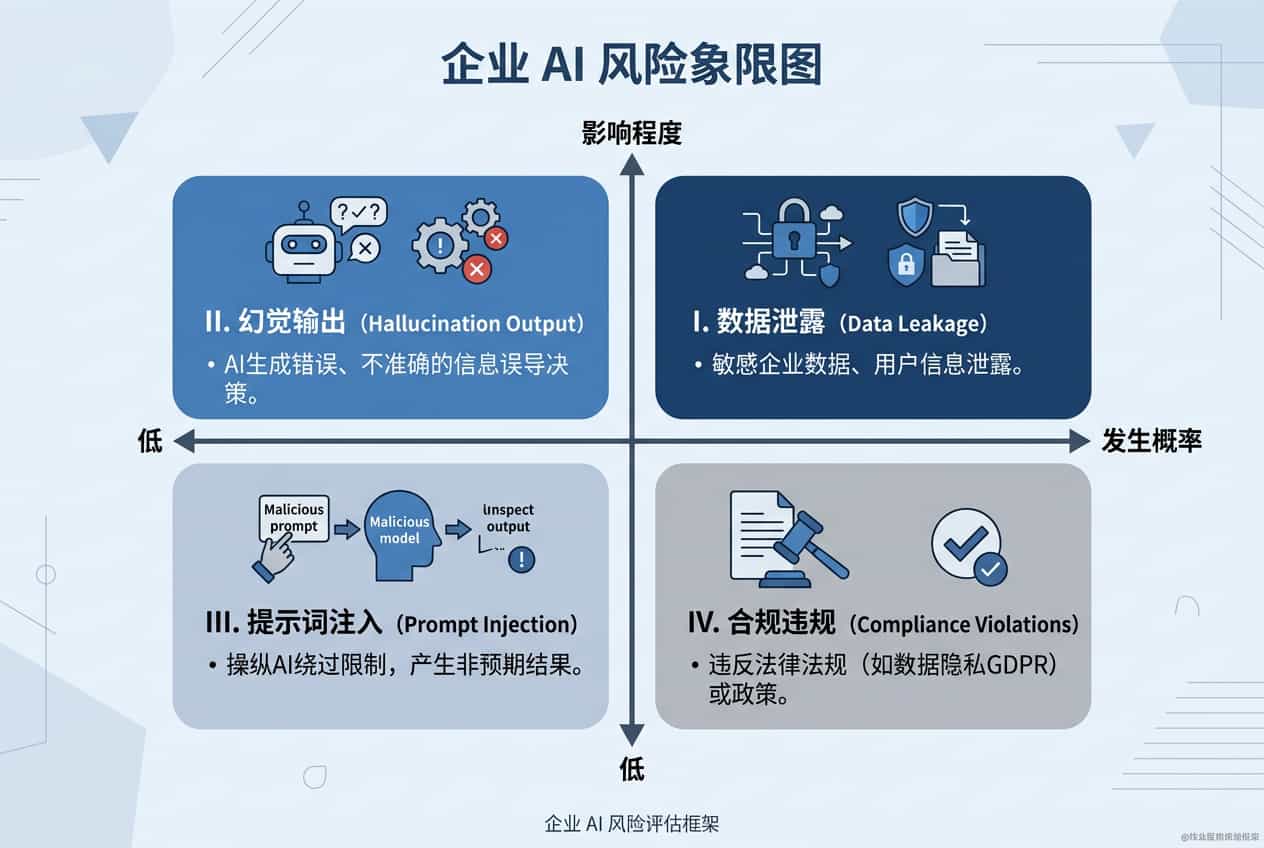
来看几个真实风险场景:
| 风险类型 | 典型案例 | 潜在损失 |
|---|---|---|
| 数据泄露 | 员工把客户合同贴进公网模型问问题 | 监管罚款 + 客户索赔 |
| 模型幻觉 | 法律助手编造不存在的判例 | 案件败诉 + 信誉受损 |
| 提示词注入 | 攻击者在文档里藏指令操控客服机器人 | 越权操作 + 数据外泄 |
| 合规违规 | 模型生成内容违反《生成式 AI 服务管理办法》 | 业务下架 |
三星 2023 年那次员工把源代码贴进 ChatGPT 的事故,
至今还被各种合规培训反复拿出来讲。
这种事不是小概率,是早晚会发生。
治理框架的四根支柱
1. 数据治理:源头别污染
模型的输出质量,七成靠数据。企业级场景里,数据治理的核心动作是三件:
- 分级分类:哪些数据可以喂给公网模型,哪些只能进私有部署,哪些根本不能进 AI。
- 脱敏管线:在数据进入 prompt 之前,自动识别并替换身份证、手机号、银行卡等敏感字段。
- 来源可追溯:每条训练或检索数据的来源、授权状态、过期时间都要有记录。
2. 模型治理:版本和评测都要管
模型不是一次性资产,它会更新、会被替换、会出现性能漂移。
一个能用的模型治理流程至少要做到:
- 模型注册表(Model Registry):每个上线模型都有唯一 ID、版本、训练数据、评测分数。
- 自动化评测:上线前跑一套包含准确性、安全性、偏见检测的固定评测集。
- 灰度发布:新版本先放 5% 流量,看 24 小时数据再放量。
3. 安全合规:把攻击面想全
大模型的攻击方式和传统应用完全不同。 OWASP 在 2025 年发布的 LLM Top 10 里,前三名分别是提示词注入、不安全的输出处理、训练数据投毒。
这只是网关层的第一道闸门,真实生产环境还要叠加输出审核、上下文隔离、权限校验。
但写过代码的你就明白一件事:安全是分层的,没有银弹。
4. 运营审计:每一次调用都要可回放
合规这事最怕的就是出问题之后说不清楚。
审计层要做的就是把每次调用的上下文都存下来:用户是谁、prompt 是什么、模型返回了什么、有没有命中安全策略、最终是否被采用。
存日志看起来简单,难的是查询和回放。
建议用列式存储 + 全文索引的组合,平时按用户、按模型、按时间多维度查,出事时能按 trace_id 把整条链路拉出来。
落地清单:先做哪几件事?
如果你公司刚开始搞,预算和人力都有限,下面这个优先级供参考:
- 先把数据分级和脱敏做掉,这是合规最低线。
- 接着上统一 AI 网关,所有应用走同一个入口,便于审计和限流。
- 然后建模型注册表和评测流水线,避免一个模型上线之后没人管。
- 最后才是红队测试和安全演练,定期请人来「攻击」自己。
很多团队顺序搞反了,先买了一堆红队工具,结果连最基本的脱敏都没做,属于本末倒置。
常见问题(FAQ)
Q1. 大模型治理和传统数据治理有什么区别?
传统数据治理管的是结构化数据的质量和权限,大模型治理还要额外管「不可解释的输出」「会被攻击的提示词」「会漂移的模型版本」这三类传统体系覆盖不到的东西。
Q2. 中小企业有必要做治理吗?
有必要,但可以轻量化。
最小可行版本是:数据分级清单 + 简单的脱敏规则 + 调用日志保留 90 天。
这三件事用一两个工程师两周就能搭出来,能挡掉 80% 的低级风险。
Q3. 私有部署的模型还需要治理吗?
需要,而且某些维度更严格。
私有部署不等于自动安全,模型权重的泄露、内部员工的滥用、上下文里的敏感信息一样会出问题。
私有化只是把数据留在了自己机房,不代表风险消失。
Q4. 提示词注入到底有多大威胁?
威胁非常实在。
攻击者可以把恶意指令藏在用户上传的文档、网页内容、甚至图片的 OCR 文本里,让模型在不知情的情况下执行越权操作。
OWASP 把它列为 LLM 应用的头号风险,不是夸张。
Q5. 治理是不是会拖慢业务上线?
短期看会,长期看反而更快。
前期建好流程,后续每个 AI 应用都能复用,安全评审从一个月缩到一周。
写在最后
企业大模型治理这件事,没有完美方案,只有不断迭代的流程。
它不应该是法务和安全部门的「附加要求」,而应该是 AI 产品经理在第一天就考虑进去的「产品能力」。
我个人觉得,未来一两年里,能不能把治理体系跑通,会直接决定一家公司 AI 项目的天花板。
技术大家都能买到,治理能力是真正的护城河。
如果你们公司在落地大模型治理时遇到了具体问题,比如脱敏方案怎么选、网关怎么设计、评测集怎么搭,欢迎在评论区聊聊
版权声明
未经授权,禁止转载本文章。
如需转载请保留原文链接并注明出处。即视为默认获得授权。
未保留原文链接未注明出处或删除链接将视为侵权,必追究法律责任!
本文原文链接: https://fiveyoboy.com/articles/enterprise-llm-governance/
备用原文链接: https://blog.fiveyoboy.com/articles/enterprise-llm-governance/